
Deep Predictive Coding Networks for Video Prediction and Unsupervised Learning
June 14, 2018
In this post I’ll review the main ideas and results from the PredNet paper [1].
Particularly, I enjoy the biologically inspired unsupervised predictive coding paradigm. I feel nature has evolved all this way aiming an efficient structure, and though it may seem hard to follow its lead, it will pay off in the long run. That’s why I’ve decided to start studying and logging (as blog posts) this realm of biologically inspired AI. Hence, this is the first from what I hope will become a series of posts.
TL’DR: Learning to predict how an object or scene will move in a future frame requires knowledge (implicit at least) of the objects that make up the scene and how they are allowed to move, and thus confers advantages in decoding latent parameters that give rise to an object’s appearance, which in turn can improve recognition performance. Hence, prediction can serve as a powerful unsupervised learning signal. Experiments using car-mounted camera videos demonstrates the network learns to predict both the movement of the camera and of objects, as well as decoding of the current steering angle through its learned representations.
Model
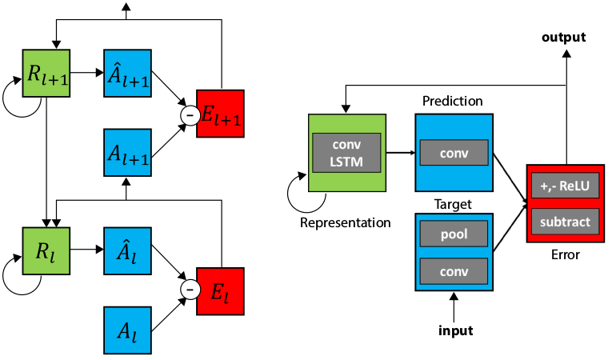
Just as most modern networks, the proposed model boils down to a hierarchical stack of basic modules that learns progressively more abstract representations. However, instead of passing along to the next layer the features generated by the current layer’s input, it forwards the error between what it predicted the features would be and what they really were.
The basic general schematic can be seen on the left of the figure bellow and is agnostic from implementation specific frameworks (i.e., deep learning and end-to-end SGD training). Such architecture is rooted on the original work of Rao and Ballard, Predictive coding in the visual cortex [2], but constructed from the modern viewpoint of deep nets.
Building blocks of the basic module that composes a layer of the model:
-
Representation R: recurrent memory that stores information about the world and gets updated by the prediction error and the upper layer representation. The authors implement it through convLSTM (Convolutional Long Short-Term Memory) [3] units, but other memories could be used;
-
Prediction Â: what the representation unit R expects to see at the next time step. Implementation-wise, it is simply the output of a single convolution stack (+ReLU) on the hidden convLSTM state;
-
Target A: this one is pretty self-explanatory, it’s what the unit R should try to output. Similarly to Â, it consists of a single conv stack on the layer’s input, but with an additional max pooling to shrink size and increase invariance of the model;
-
Error E: pointwise difference between the target A and the prediction Â, which is forwarded as input to the next layer. Error is further separated into its positive and negative components, which according to [1] represents that those values are coded by different neurons in the cortex (e.g., on-center, off-surround and off-center, on-surround V1 neurons).
The loss function used for training is the weighted sum across all layers $l$ and time steps $t$ of the mean error $E^t_l$ in each unit: $\sum_t \lambda_t \sum_l \frac{\lambda_l}{n_l} \sum_{n_l} E^t_l $. To make things simpler, at the first time step there is no penalty since there is nothing really to compare to (the error is the target itself), so $\lambda_t = 0 $. Moreover, only two configuration of weight for the layers are used: the first layer $l_0 $ with weight $\lambda_0 = 1 $ and the others with either no weight at all ($ \lambda_l = 0 $) or one order of magnitude smaller ($ \lambda_l = 0.1 $, named $L_0 $ and $L_{all} $, respectively. The authors claim that using the same weight across all layers led to results considerably worse. This behavior intuitively makes sense because we are only using the prediction of the lowest (first) layer as the output of the model (next-frame prediction) and thus focusing on the first layer only leads to better predictions. However, as we shall see, this is not true when one tries to explain the latent factors instead.
Experiments
Two main experiments are conducted. The first, with synthetic image sequences (of rotating faces) and known latent factors (angles, velocities and faces’ eigenvalues), allows us to peek into the latent parameters of the representation units and check whether they encode essential information about the sequences (i.e., the latent factors used to generate them). The second, studies the behavior of the model on real natural scenes with ego-motion (self-driving cars).
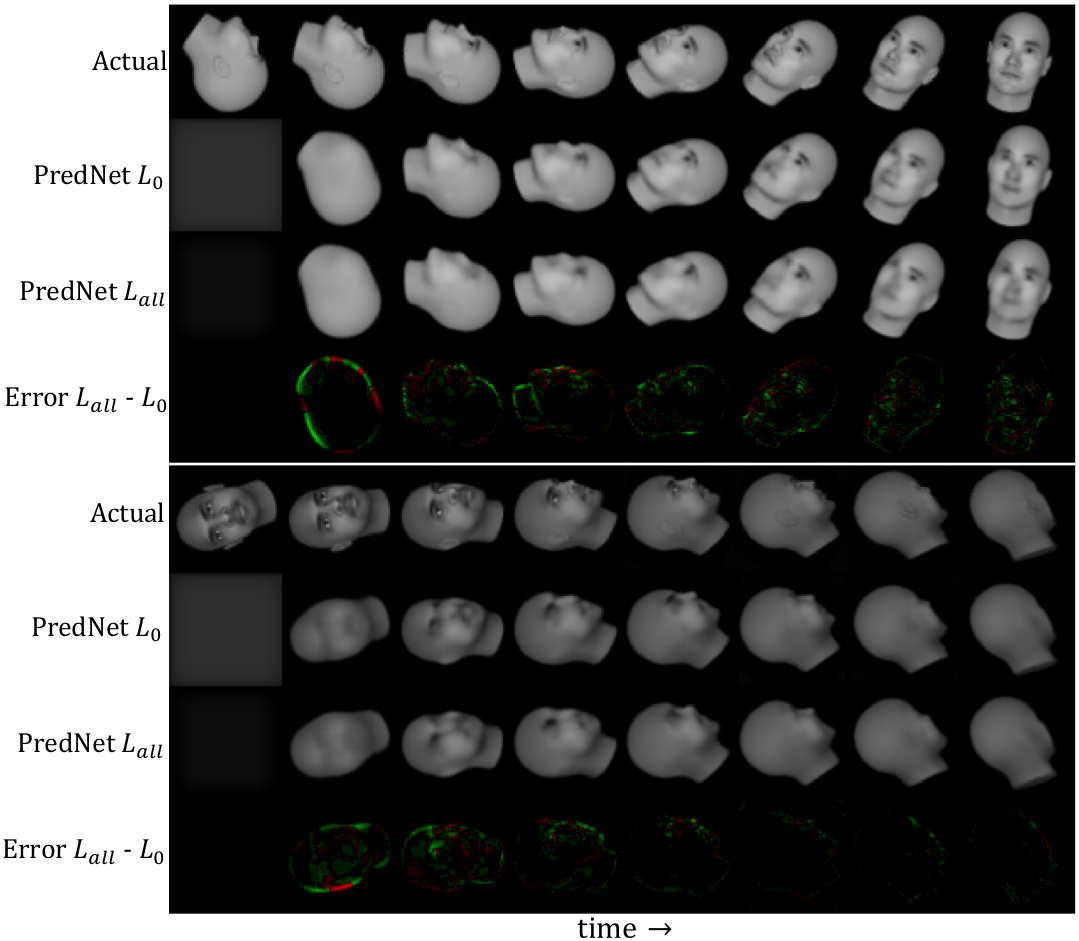
The image bellow shows the predictions of the models trained with loss functions $L_0 $ and $L_{all} $ explained above, as well as the difference between them (green corresponds to regions where $L_0 $ was better and red the other way around). We can clearly notice that $L_0 $ has finer details (e.g., lips and eyes). Another interest aspect is that the predictions gets progressively better as the models accumulate more and more information about the scene and its components.
Then, the authors try to assess if the models learn about the latent factors that define the sequence (angles, velocities and faces’ identities). Hence, they use a ridge regression to decode the hidden states of the representation units at the first and second time steps, which encode static and dynamic parameters, respectively. They verify that the best results, specially for the face identity, come from the features extracted from the $L_{all} $ model. Furthermore, this analysis suggests that the trained models learn representations which can be more easily linearly decoded and may generalize well to other tasks. Indeed, training a linear SVM to classify the face identity from a single image shows that $L_{all} $ gives the best results, even when compared to a standard autoencoder and a variant of Ladder Network [2].
The second experiment consists of test PredNet on complex, real-world sequences of car-mounted camera videos, which presents rich details and temporal dynamics. They train on the KITTI dataset [4] and test on the CalTech Pedestrian dataset [5]. The models make fairly accurate predictions, predicting the trajectory of moving and turning cars, the appearances of shadows and filling in the ground. Also, we can again verify the same behavior as before with the synthetic sequences of rotating faces, the $L_{all} $ model slightly underperforms its $L_0 $ counterpart, and both have better results than a similar model that just forwards to the above layer the target activations instead of the prediction error. However, when compared to the architecture of [6] on the Human3.6M dataset [7], PredNet has worse performance (without re-optimizing hyperparameters to this dataset), which is a bit disappointing.
Although trained to predict only a single frame ahead, we can feed the prediction back to the model’s input so that it can recursively predict multiple frames ahead. What’s more, we can finetune the model to handle such situation and get better, less blurry predictions (figure below). Naturally, as time goes by, the model starts to break down and predictions get blurrier. Actually, the mean square error (MSE) of the extrapolated predictions grows almost linearly with time. Nevertheless, the model gets the key structures of the scene right (i.e., the tree shadow in the first sequence of the figure bellow).

That’s all folks. I hope you enjoy reading. Any suggestions, critiques or advices, you are more than welcome to comment.
References
[1] William Lotter, Gabriel Kreiman, David Cox. “Deep Predictive Coding Networks for Video Prediction and Unsupervised Learning”. International Conference on Learning Representations (ICLR), 2017. (PreNet project GitHub page)
[2] Rajesh Rao and Dana Ballard. “Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects”. Nature Neuroscience, 1999.
[3] Xingjian Shi, Zhourong Chen, Hao Wang, Dit-Yan Yeung, Wai-Kin Wong, and Wang-chun Woo. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Advances in neural information processing systems (NIPS), 2015.
[4] Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset. International Journal of Robotics Research (IJRR), 2013.
[5] Piotr Dollár, Christian Wojek, Bernt Schiele, and Pietro Perona. Pedestrian detection: A benchmark. Conference on Computer Vision and Pattern Recognition (CVPR), 2009.
[6] Chelsea Finn, Ian Goodfellow, and Sergey Levine. Unsupervised learning for physical interaction through video prediction. Advances in neural information processing systems (NIPS), 2016.
[7] Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. “Human3.6m: Large scale datasets and predictive methods for 3d human sensing in natural environments”. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 2014